Query Representation
To adapt query distribution according to the current network load, the Adaptive System Communication monitors channel status on each wireless link and imposes bandwidth limitation on sending operations. By monitoring pending messages and bandwidth, SALES obtains indications about the current channel status that can be useful to adapt context data distribution and to trigger query adaptation.
Above all, SALES reduces bandwidth requirements by tailoring query representation. Given a particular context data type, a context query represents some context data needs by imposing constraints on the values assumed by the attributes belonging to the data instance. Traditionally, each context query contains a set of basic constraints, e.g., membership tests, range tests, and so forth, arranged by AND-/OR-operators, and is transmitted between different nodes using traditional serialization mechanism. When the wireless channel is highly congested and the query contains membership tests, we can take advantage by Bloom filters.
A Bloom filter is a space-efficient probabilistic data structure useful to support membership queries on a set A={a1, a2, …., an} of n keys. Each filter is a vector of m bits, initially all set to 0, computed by applying k independent hash functions {h1,h2,….,hk} to each key in the original set. The filter associated with the keyset is obtained by setting to 1 all bits at positions h1(a), h2(a), ..., hk(a) for each element a in A. Given a query for a generic key b, we check all the bits at positions h1(b), h2(b), ..., hk(b) and, if any of them is 0, then certainly b is not in the original set. Otherwise, we assume that b is in the set, although it may not be the case because we may have false positive events. If membership tests are involved and if it is possible to define hash functions for involved attributes, during query distribution, the Query Adaptation Module can transform the involved membership tests by introducing Bloom filters.
In particular, SALES adopts Bloom filters in two different ways (see the figure below):
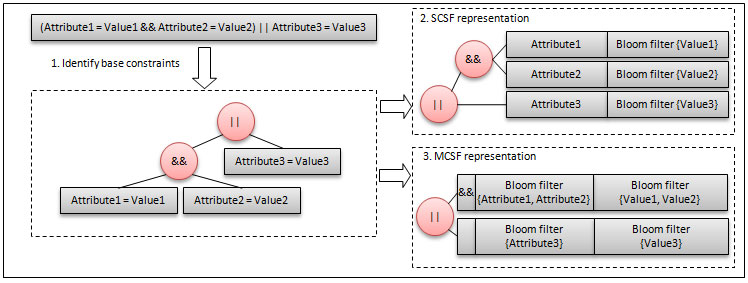
- Single Constraint - Single Filter (SCSF): This modality maps each membership test to a proper name-filter pair.
- Multiple Constraints - Single Filter (MCSF): This modality maps different membership tests (tied by the same logical operator) to only two Bloom filters. The first filter is used to select the attributes involved, while the second one is used to constraint the attribute values.
These two modalities are used in conjunction with the uncompressed one, and are adopted dynamically during message routing.