IHMAS Experimental Results
|
IHMAS Experimental Results |
|
We have tested and evaluated IHMAS in a wireless test-bed consisting of several Windows and Linux client laptops equipped with IEEE 802.11b Cisco Aironet 350 Wi-Fi cards and Mopogo BT dongles. About software infrastructure configuration we have employed OpenIMSCore; we have implemented ASSC in Java by exploiting the portable Java API for Integrated Networks (JAIN) SIP implementation by the National Institute of Standards and Technology; our AMG implementation is based on Asterisk; our MNs exploit our extended version of IMS Communicator that is a pure Java IMS client based on SUN Java Media Framework and JAIN SIP with IMS SIP extensions by 3GPP and IETF.
In the following, we report experimental results about IHMAS audio streaming adaptation and session continuity. Then, we report recent collected results about recently proposed IHMAS PS optimizations. | ||
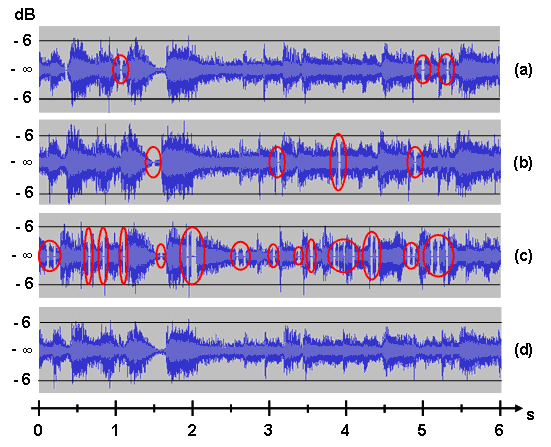
Audio Streaming Session continuity in IHMAS This section reports experimental results that point out how IHMAS operations for content adaptation can grant continuous service delivery even during vertical handoffs. Reported experimental results are averaged over 1,000 handoff cases, while provisioning an Audio on Demand (AoD) service offering two types of flows: high-quality ULAW-encoded flows with constant frame rate = 50 frames/s, buffer slots storing ULAW/RTP (216B payload per packet), and 64Kbps bandwidth; and low-quality GSM-encoded flows with the same constant frame rate, buffer slots storing GSM/RTP packets (89B payload per packet), and 13,2Kbps bandwidth. All experimental results have been collected for vertical handoffs in the direction from Wi-Fi to BT, which is the most challenging case because it requires to apply content adaptation actions not required in the other direction (due to Wi-Fi higher capacity) and due to the longer time for the BT client card to connect to its BT AP. The following figure shows the same portion (6s) of audio stream collected at MN in four different scenarios: (a) the reported wave corresponds to a ULAW-encoded stream delivered over the Wi-Fi infrastructure loaded with a background traffic of 2Mbps; (b) the wave represents a ULAW-encoded stream soon after the vertical handoff event towards an unloaded BT network; (c) is the same as (b) except for an additional background traffic (35Kbps); (d) has the same operating conditions of (c) but with AMG that dynamically downscales ongoing audio flows from ULAW to GSM. Red circles facilitate the understandability of the figure by clearly pointing out the time intervals when intermittent playout discontinuities are present. The reported results confirm the effectiveness of our proposal. In (a) the Wi-Fi network capacity and robustness grant only a few sporadic discontinuities. In (b), the ideal delivery conditions (without background traffic) guarantees only a few traffic discontinuities. But if we repeat the (b) test in more realistic conditions with (even low) background traffic, i.e., the (c) scenario, we have experimented that it is impossible to maintain ULAW delivery continuity, mainly due to BT scheduling problems. AMG activation, instead, permits to dynamically adapt streaming provisioning and to grant service continuity even in this challenging situation, see the figure below, graph d. |
||
|
||
We also evaluated the effectiveness of the IHMAS audio adaptation approach from the point of view of final users’ perception and shows how our adaptation operations improve the subjective quality impression perceived at endpoints.
The aim was to confirm the quantitative results obtained in our previous experiment especially for (c) and (d) scenarios. In fact, GSM encoding guarantees audio stream continuity but with lower quality if compared to ULAW. In order to validate our prototype also in relation to final users’ satisfaction, we have adopted the standard subjective measurements proposed by ITU, called Multiple Stimuli with Hidden Reference and Anchor (MUSHRA), and prepared different listening sessions submitted to 10 non-expert human operators by using the RateIt program. The MUSHRA test requires the operators to give a score in a linear [0, 100] range divided in five values: bad [0, 20[, poor [20. 40[, fair [40, 60[, good [60, 80[, and excellent [80, 100]. We measured: a mean score of 75.3 (good) for the (a) scenario; 72.3 (good) for (b); 5.4 (bad) for (c); and, most relevant to motivate our dynamic adaptation operations, 64.3 for (d). That evaluation is obviously lower than (a) but, thanks to runtime GSM transcoding, the overall quality is still perceived as good. |
||
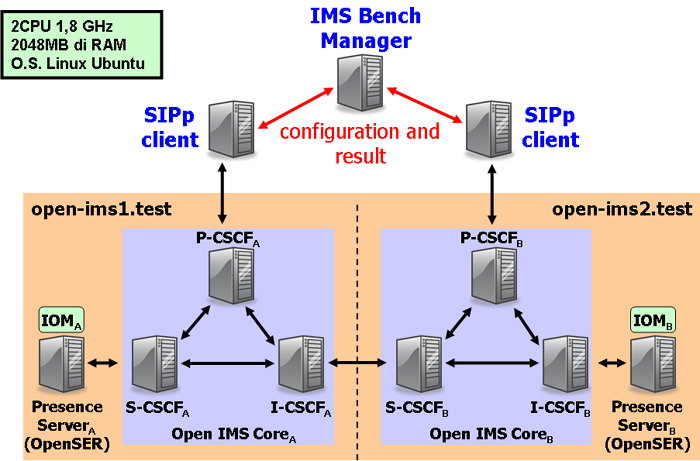
IHMAS PS Optimizations: IOM Performance Results The section shows collected results about IHMAS PS optimization. We have thoroughly tested and evaluated the scalability performance of our solution by validating it over our multi-domain IMS testbed deployment. Our IMS infrastructure components run on Linux boxes each equipped with two 1.8 GHz CPUs and 2048MB RAM. The distributed testbed consists of two domains (domainA and domainB) that follow the IMS-based PS specifications. For each domain, the IMS core components (P-/I-/S-CSCFs and HSSs) run each on a single host, while IOM and PS execute together on a dedicated host (see the figure below). To test inter-domain system scalability, we employed the IMS Bench SIPp, an IMS traffic generator that conforms to the ETSI TS 186 008 IMS/NGN Performance Benchmark specification. IMS Bench SIPp permits to define benchmark configuration scenarios that correspond to different IMS session phases (e.g., registration, subscription, …). |
||
|
||
In the experiments, we defined three main phases. In the first phase, IMS clients register with a constant arrival rate of 10 call per second (cps); this phase lasts 15s and registers 150 clients equally distributed over the two domains. In the second phase, all watchers subscribe to the presentities: in our case, all watchers belong to domainA and all presentities to domainB; in addition, we tuned phase duration to obtain different number of subscriptions for single presentity, i.e., watcher/presentity (w/p) factor. Finally, during the third phase, presentities inject PUBLISH messages.
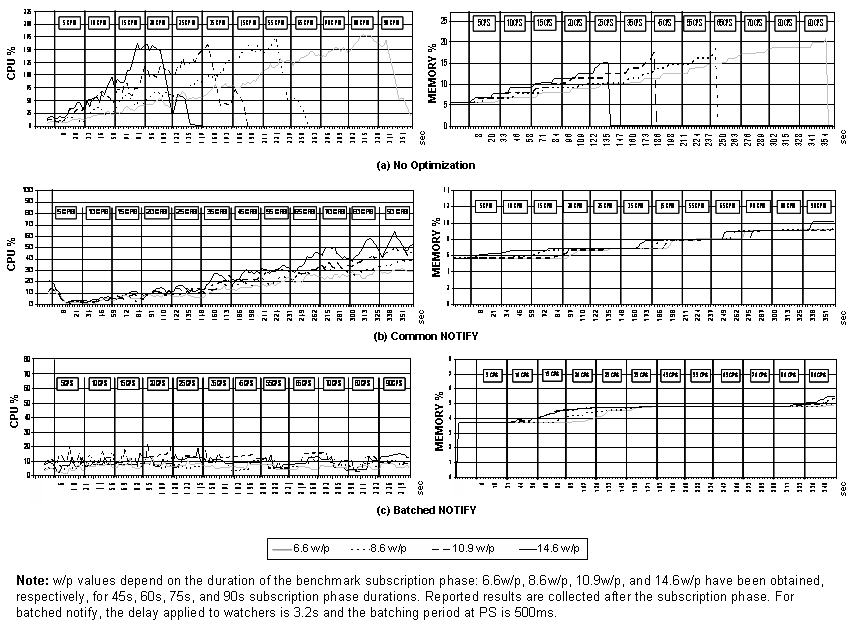
About the local workload in inter-domain PS routing, we report results about the most overloaded component: the external S-CSCF (see the optimized IHMAS protocol shown reported here). The same considerations also apply to other components, such as the local S-CSCF in the non-optimized PS scenario. The following figure reports CPU and memory utilization (from 0 to 200%, summing up the usage percentage of the two CPUs) for our benchmark phases. In particular, the third phase was configured with 12 incremental steps with 30s of duration, going from 5cps to 90cps according to a Poisson distribution. After a preliminary evaluation of the system scalability threshold, we have determined four w/p thresholds (i.e., 6.6, 8.6, 10.9, and 14.6w/p) to increasingly stir the system up to its upper limit. Without any PS enhancements, S-CSCF cannot terminate step 12 and collapses respectively at 353s, 244s, 183s, and 137s for 6.6, 8.6, 10.9, and 14.6w/p (see graph a below). IOM activation can greatly improve system scalability; in particular, the common and batched NOTIFY enhancement (see graphs b and c) can effectively drop both CPU and memory usage at S-CSCF, by decreasing the number of NOTIFY messages exchanged. The bursty CPU trend in graph c is due to notification batching at IOM; however, the CPU oscillation interval is modest and its peaks are always under 20% (much lower than the peaks usually due to common NOTIFY optimization). |
||
|
||
Even at the saturation threshold without PS enhancements, IOM continues to work properly and avoids congestion of inter-domain IMS components at an acceptable overhead cost. In particular, the system with our enhancements saturates only at a PUBLISH rate of 250cps with 14.6w/p (not shown in figure); at this point the CPU usage at PS is always below 120% for common NOTIFY, while it slightly increases to 140% for batched NOTIFY. However, thanks to its ability of better distributing inter-domain network load over time, NOTIFY batching has demonstrated to be less prone to PUBLISH message peaks. In both cases, IOM presents a limited overhead and most CPU overhead is due to database access: 80% for 250*14.6=3650 accesses per second.
|
||
|
||
| 2-feb-10 |